tensor([ 11, 24, 49, 8, 2, 253, 219, 6, 4, 165, 8, 2, 410, 6,
4, 564, 971, 27, 2, 27, 568, 6, 4, 192, 1, 45, 51, 208,
65, 235, 54, 14, 20, 867, 34, 43, 183, 1, 45, 51, 208, 65,
235, 54, 14, 20, 178, 34, 4, 676, 1, 42, 237, 2, 153, 192,
20, 3, 107, 7, 75, 17, 4, 612, 441, 549, 2, 88, 46, 3,
207, 63, 185, 55, 2, 42, 243, 3, 400, 7, 58, 33, 50, 172,
251, 84, 26, 2, 60, 6, 2, 24, 1, 4, 402, 970, 1, 1,
3, 68, 26, 2, 27, 94, 118, 8, 14, 101, 311, 10, 2, 237,
5, 422, 269, 44, 154, 54, 19, 1, 4, 308, 342, 1, 3, 79,
8, 14, 45, 159, 2, 121, 27, 190, 44, 598, 5, 325, 75, 70,
2, 105, 189, 231, 1, 241, 81, 19, 31, 1, 193, 2, 54, 81,
9, 134, 4, 174, 12, 17, 1, 390, 1, 159, 2, 27, 32, 2,
119, 1, 68, 8, 2, 410, 6, 2, 27, 8, 1, 5, 2, 159,
174, 12, 1, 168, 2, 27, 7, 69, 2, 40, 6, 1, 17, 81,
40, 19, 246, 73, 83, 64, 5, 129, 56, 8, 2, 27, 7, 33,
73, 71, 57, 5, 82, 2, 9, 6, 1, 4, 1, 59, 382, 5,
113, 8, 276, 258, 1, 317, 928, 284, 10, 784, 294, 462, 483, 7,
1, 15, 3, 16, 37, 112, 5, 677, 144, 1, 26, 2, 60, 6,
2, 24, 15, 47, 18, 70, 2, 105, 429, 15, 35, 448, 1, 5,
493, 37, 54, 62, 68, 25, 1, 33, 5, 325, 70, 15, 134, 2,
174, 232, 406, 15, 341, 134, 1, 691, 2, 27, 7, 15, 1, 10,
93, 15, 3, 25, 216, 8, 2, 24, 2, 13, 30, 23, 10, 1,
3, 21, 11, 12, 28, 76, 2, 14, 130, 19, 38, 6, 106, 14,
2, 13, 36, 3, 21, 31, 4, 9, 91, 180, 1, 137, 1, 2,
87, 97, 21, 5, 1, 285, 43, 1, 511, 569, 15, 775, 140, 1,
2, 27, 7, 25, 68, 31, 184, 31, 2, 159, 174, 12, 1, 2,
42, 1, 2, 9, 6, 1, 4, 1, 59, 8, 276, 258, 3, 489,
37, 753, 544, 10, 4, 975, 313, 26, 2, 60, 6, 2, 24, 15,
3, 16, 37, 112, 110, 32, 151, 70, 2, 24, 49, 15, 47, 15,
3, 79, 8, 14, 191, 31, 2, 42, 105, 189, 231, 15, 647, 2,
12, 8, 2, 19, 94, 118, 35, 1, 5, 54, 19, 7, 141, 2,
27, 15, 1, 31, 2, 12, 347, 81, 54, 7, 90, 8, 2, 410,
6, 2, 27, 15, 503, 62, 154, 25, 143, 1, 15, 157, 134, 2,
174, 12, 17, 81, 390, 7, 1, 16, 111, 15, 168, 2, 27, 15,
588, 329, 117, 7, 3, 163, 5, 113, 947, 175, 26, 4, 643, 1,
2, 13, 30, 23, 10, 1, 3, 21, 52, 12])



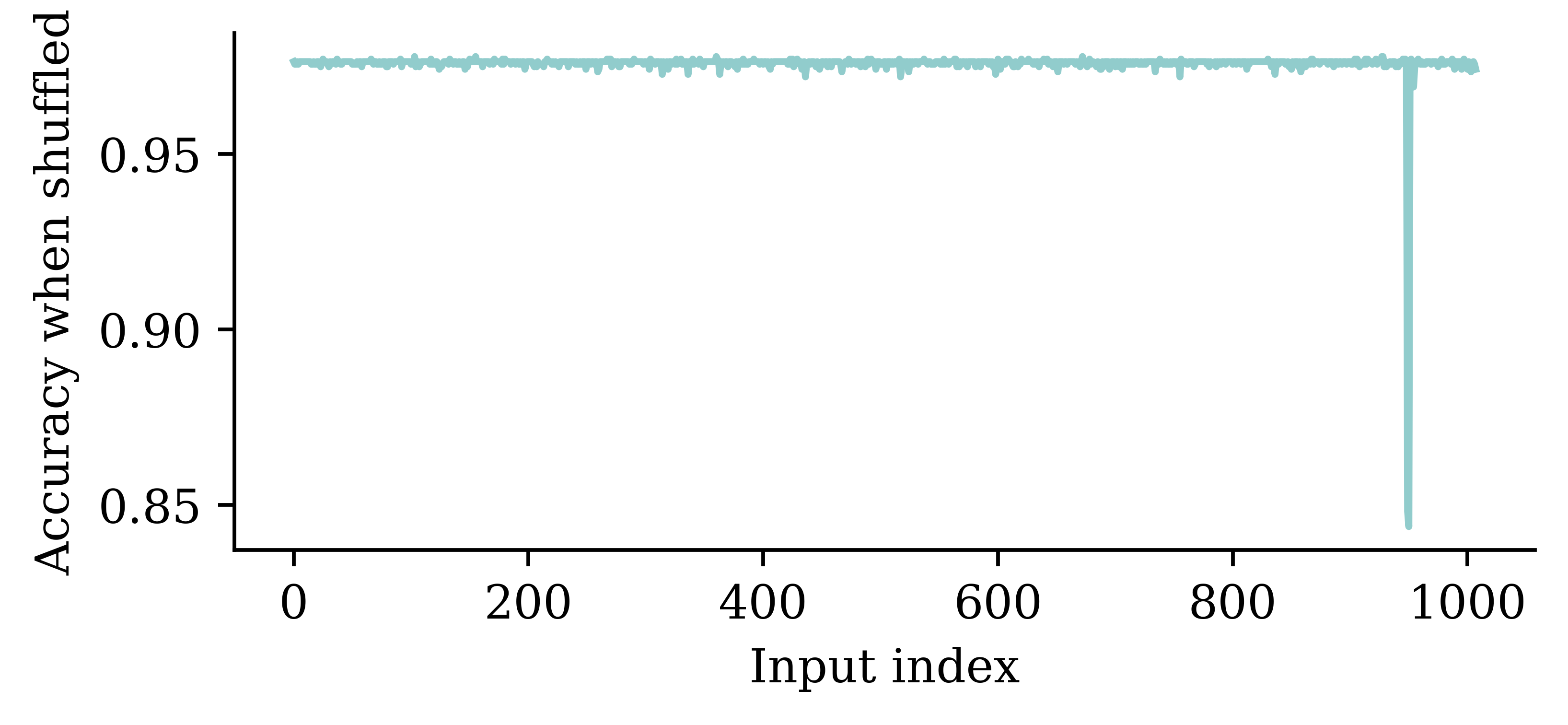

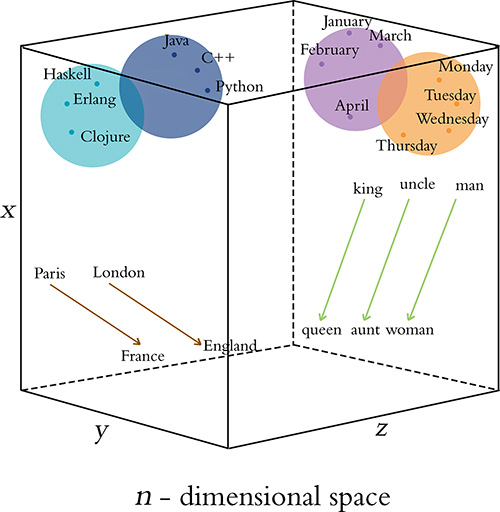
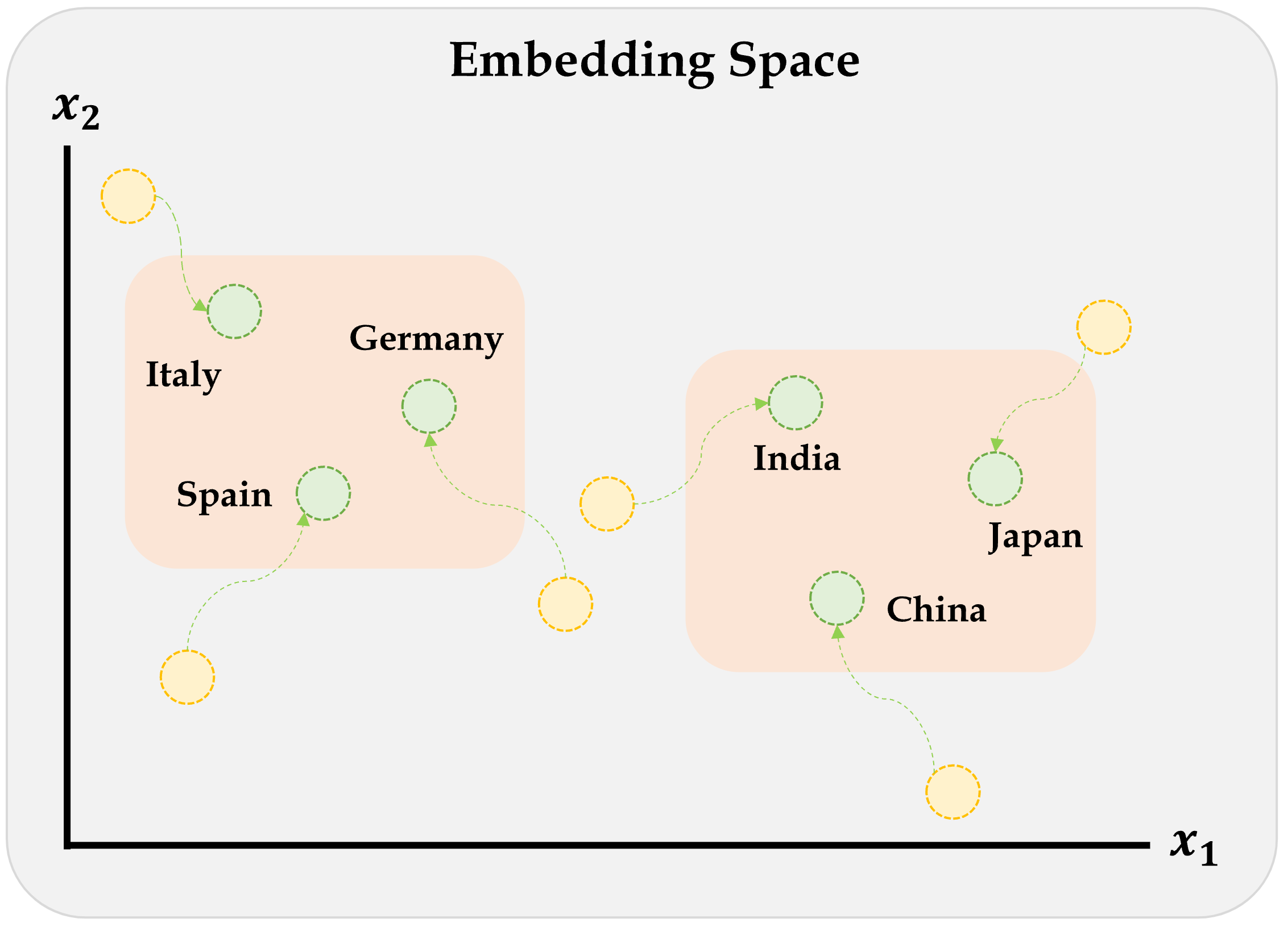

{kind=link}