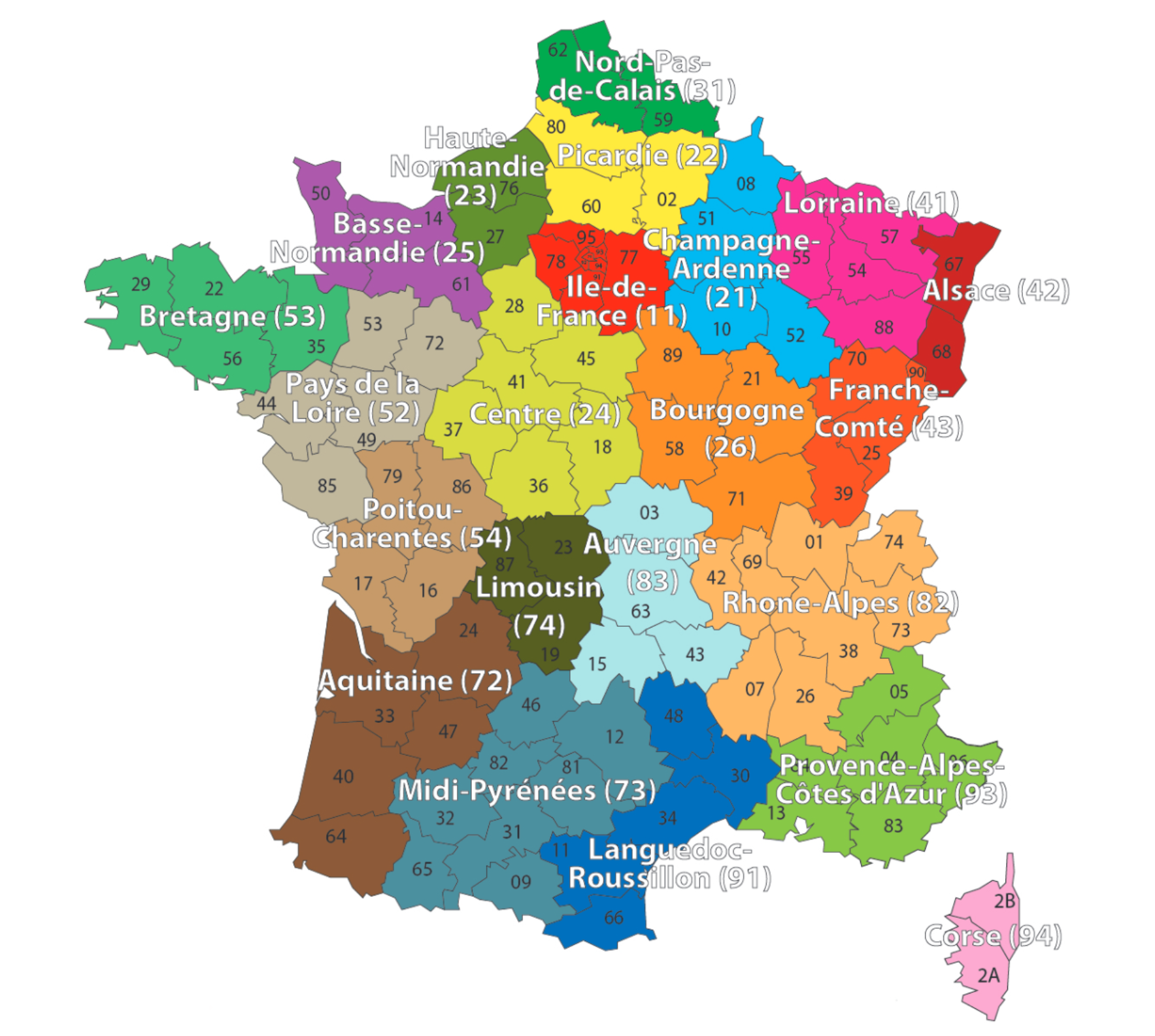
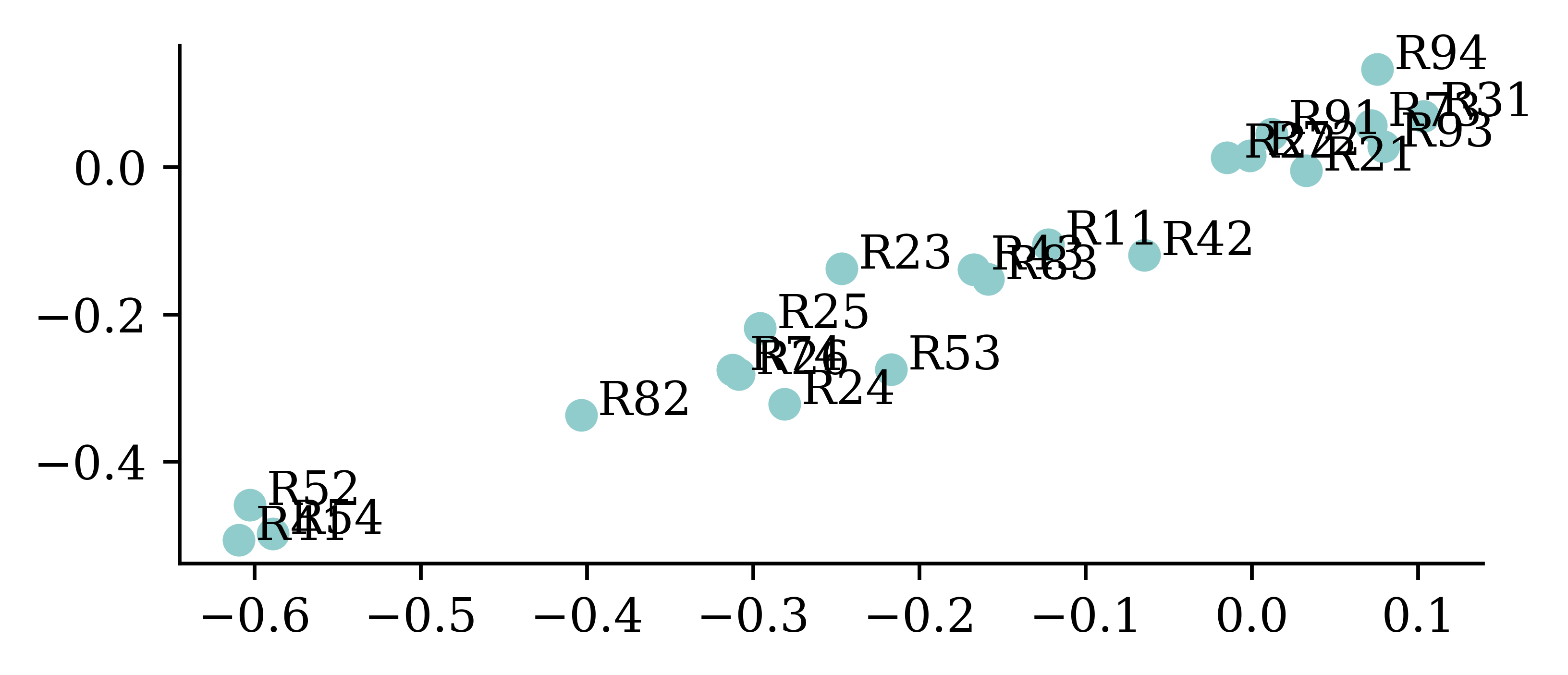
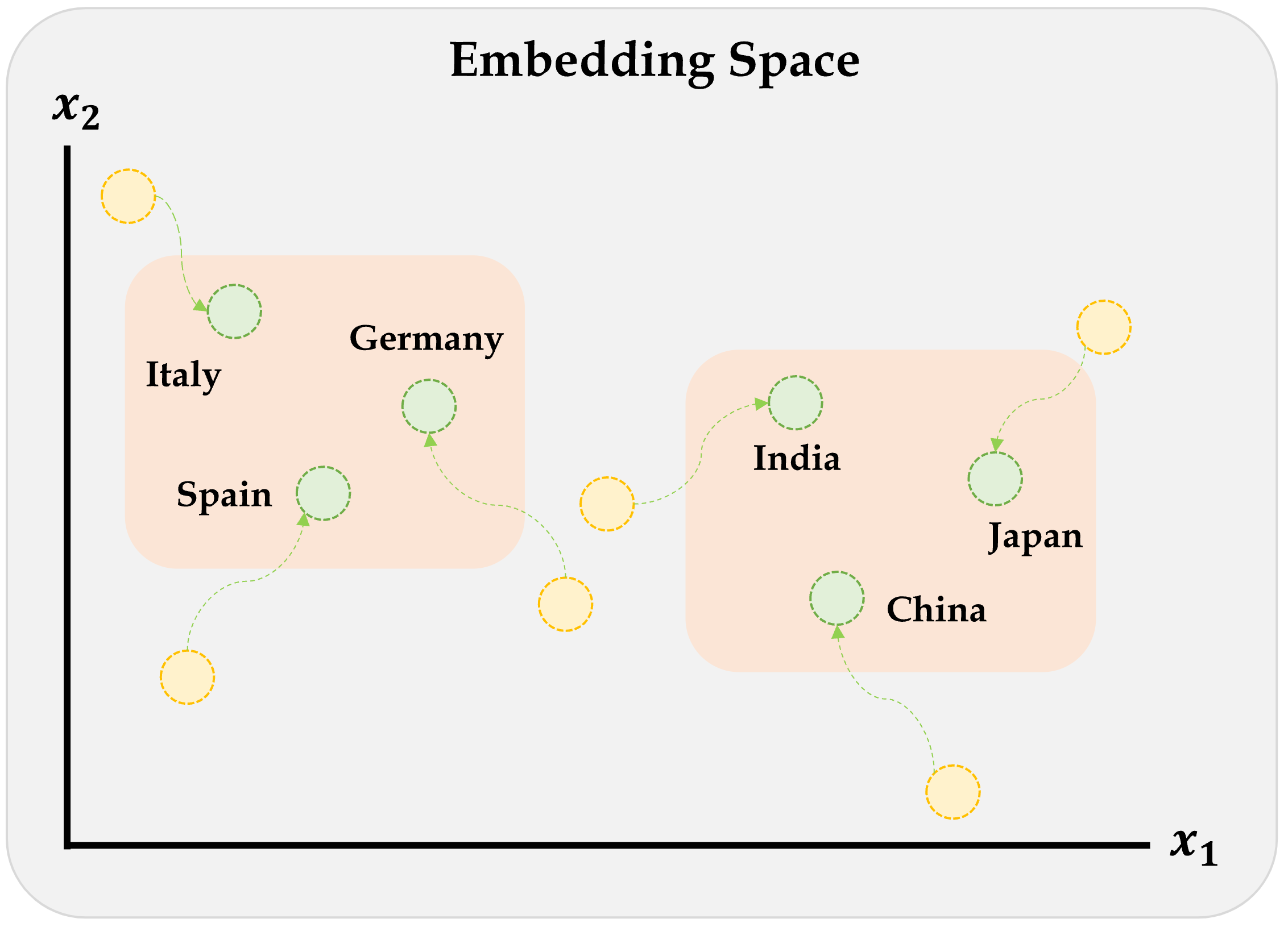
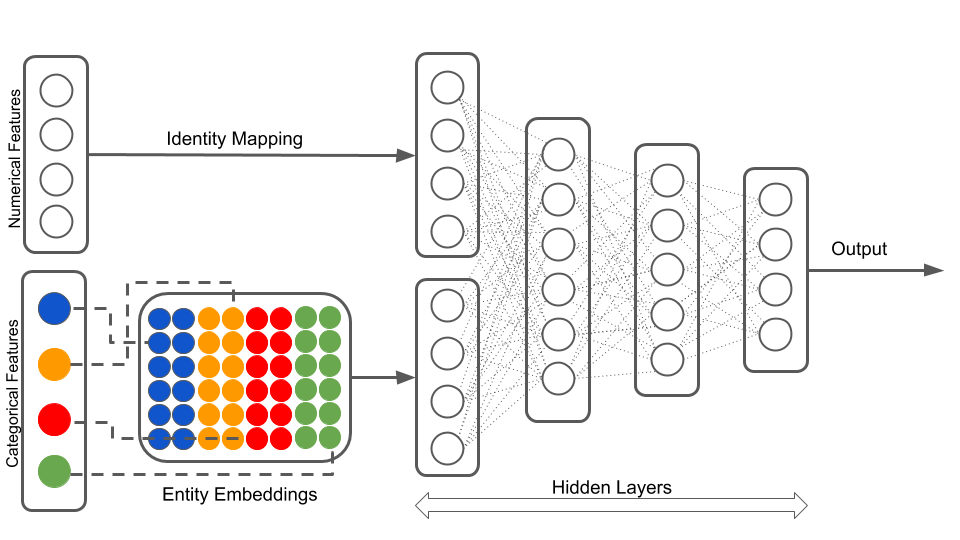
array([[ 0.13, -0.64, 0.89, -0.4 ],
[ 1.15, 0.67, -0.44, 0.62],
[ 0.18, 0.68, 1.52, -1.62],
[ 0.77, -0.82, -1.22, 0.31],
[ 0.06, 1.46, -0.39, 2.83],
[ 2.21, 0.49, -1.34, 0.51],
[-0.57, 0.53, -0.02, 0.86],
[ 0.16, 0.61, -0.96, 2.12],
[ 0.9 , 0.2 , -0.23, -0.57],
[ 0.62, -0.11, 0.55, 1.48],
[ 0. , 1.57, -2.81, 0.69],
[ 0.96, -0.87, 1.33, -1.81],
[-0.64, 0.87, 0.25, -1.01],
[-1.19, 0.49, -1.06, 1.51],
[ 0.65, 1.54, -0.23, 0.22],
[-1.13, 0.34, -1.05, -1.82],
[ 0.02, 0.14, 1.2 , -0.9 ],
[ 0.68, -0.17, -0.34, 1. ],
[ 0.44, -1.72, 0.22, -0.66],
[ 0.73, 2.19, -1.13, -0.87],
[ 2.73, -1.82, 0.59, -2.04],
[ 1.04, -0.13, -0.13, -1.36],
[-0.14, 0.43, 1.82, -0.04],
[-0.24, -0.72, -1.03, -1.15],
[ 0.28, -0.57, -0.04, -0.66]])