Generative Networks
ACTL3143 & ACTL5111 Deep Learning for Actuaries
Word-level language model
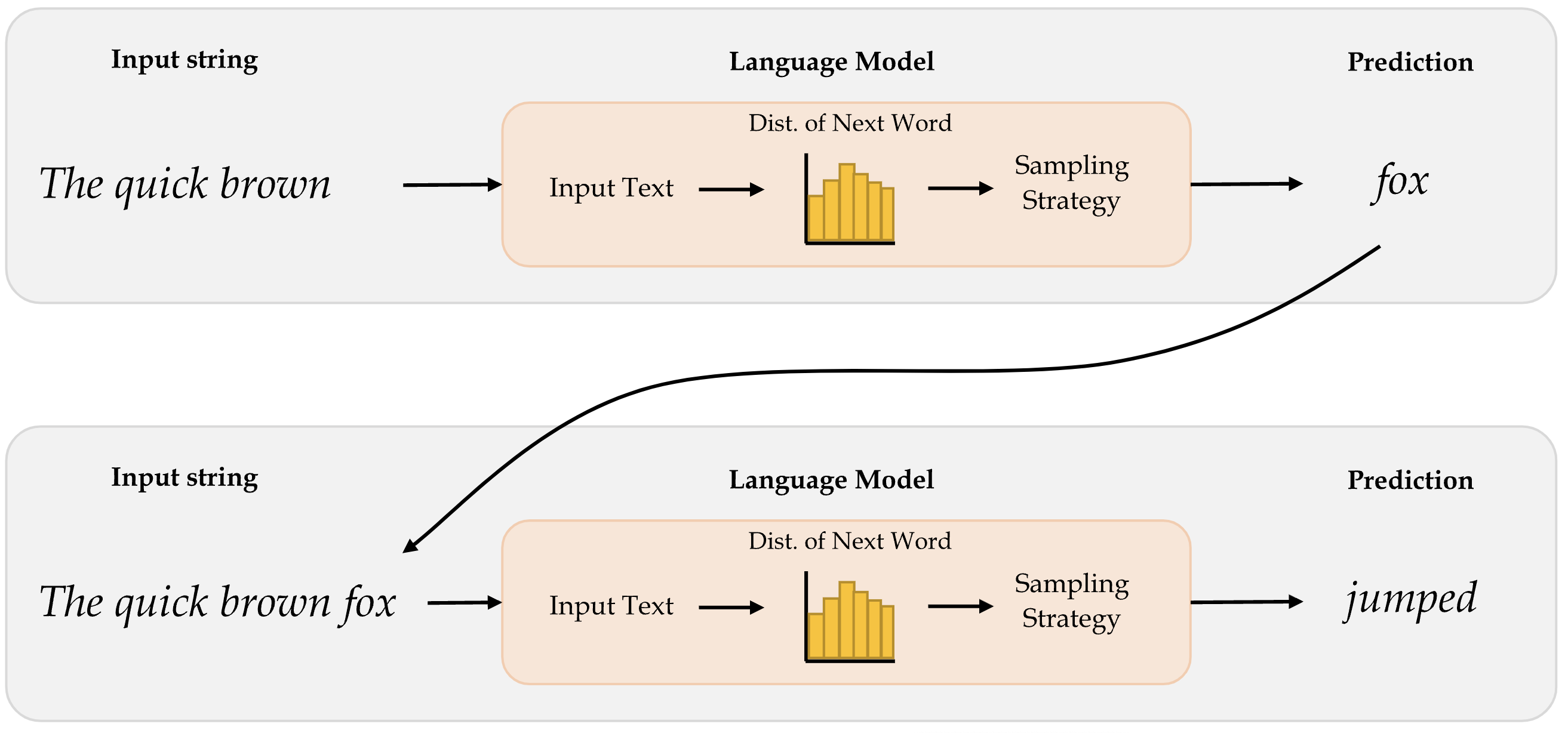
Diagram of a word-level language model.
Character-level language model
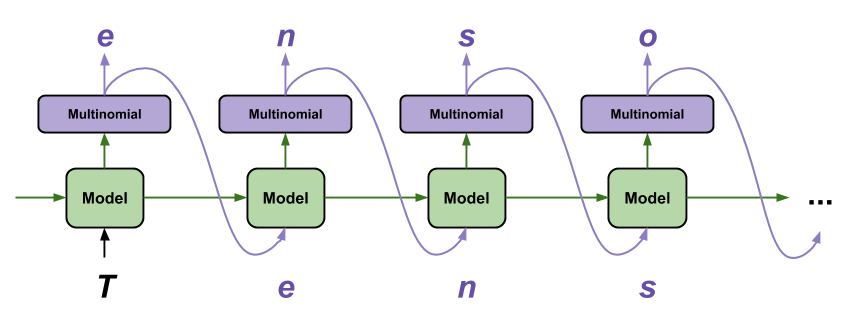
Diagram of a character-level language model (Char-RNN)
“I am a” …

Generate the most likely sequence
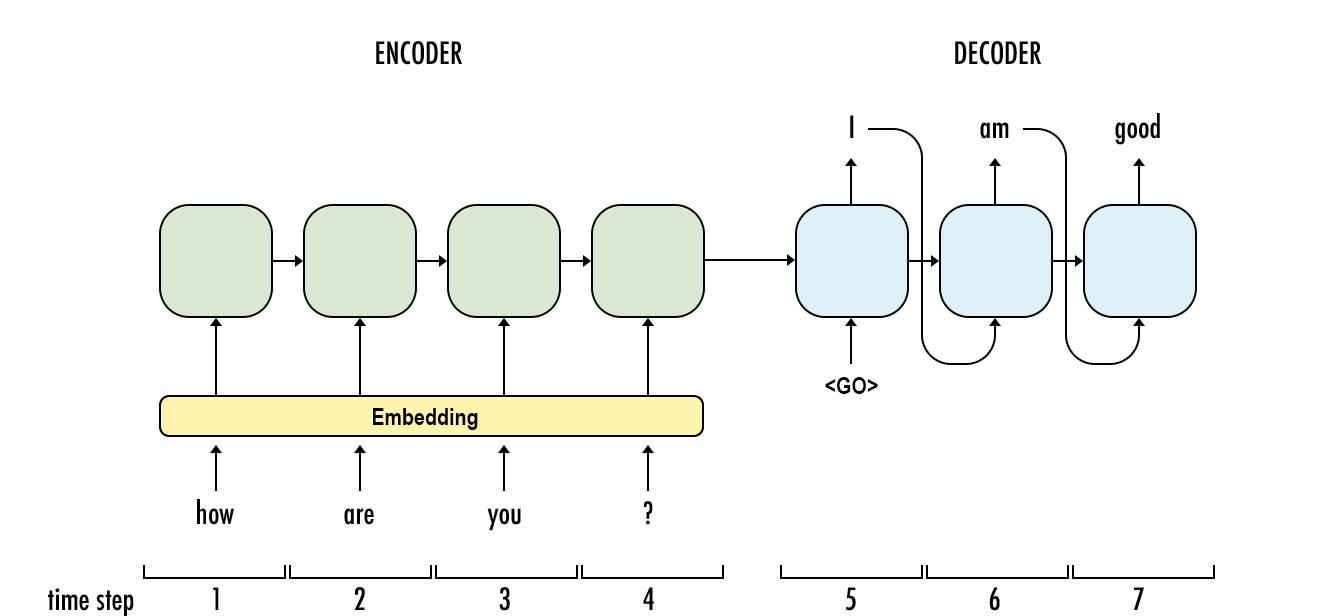
An example sequence-to-sequence chatbot model.
Beam search
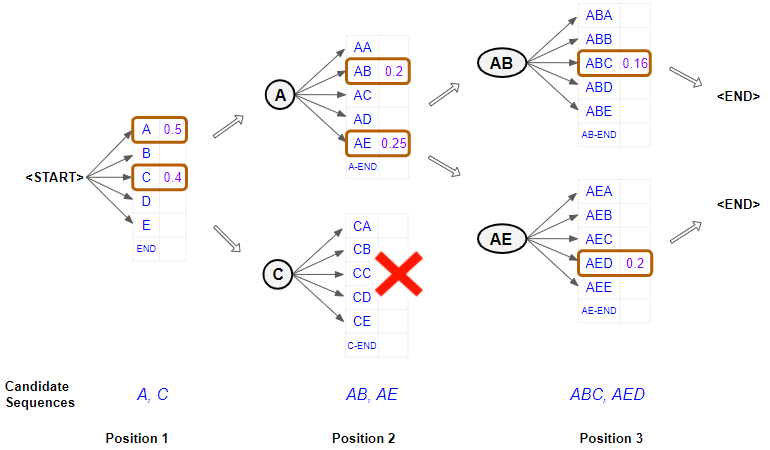
Illustration of a beam search.
ChatGPT internals
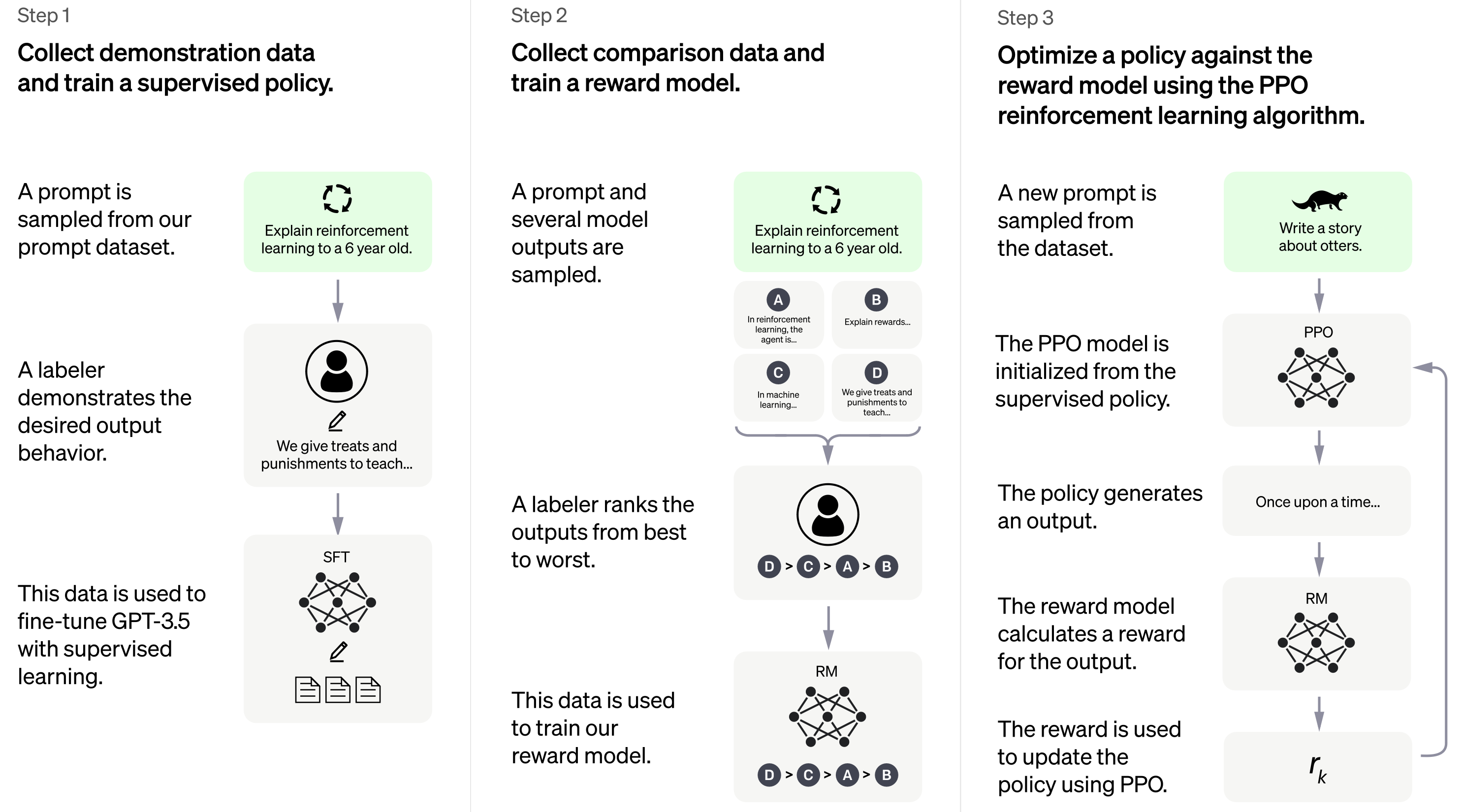
It uses a fair bit of human feedback
Adversarial examples

A demonstration of fast adversarial example generation applied to GoogLeNet on ImageNet. By adding an imperceptibly small vector whose elements are equal to the sign of the elements of the gradient of the cost function with respect to the input, we can change GoogLeNet’s classification of the image.
Adversarial stickers
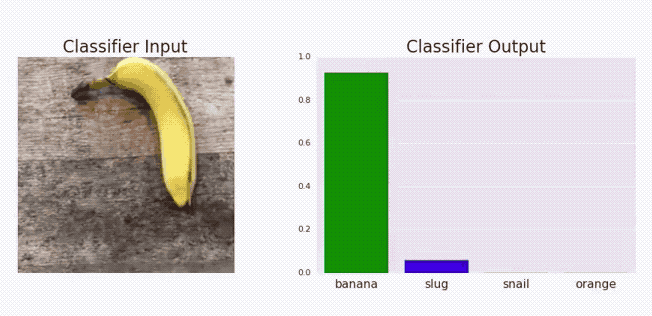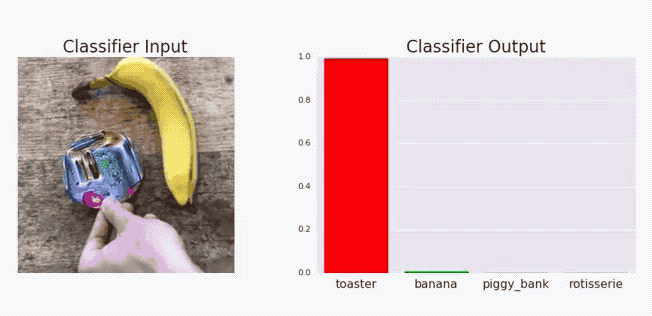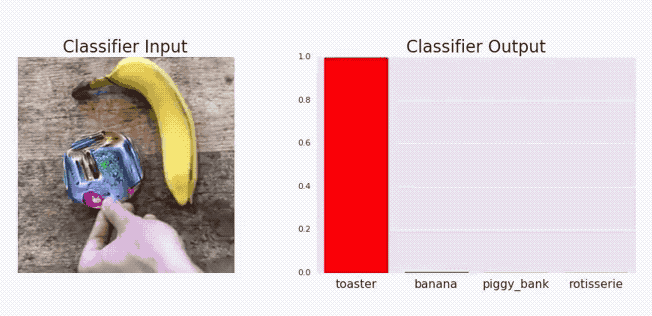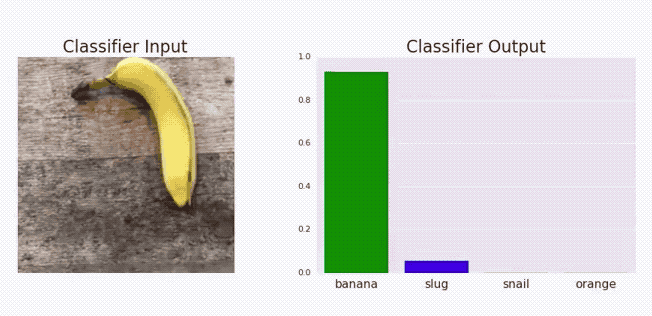
Adversarial stickers.
Adversarial text
“TextAttack 🐙 is a Python framework for adversarial attacks, data augmentation, and model training in NLP”

Demo
Deep Dream

Deep Dream is an image-modification program released by Google in 2015.
Original

A sunny day on the Mornington peninsula.
Transformed

Deep-dreaming version.
Neural style transfer
Applying the style of a reference image to a target image while conserving the content of the target image.
An example neural style transfer.
A wanderer in Greenland
Content

Style

A wanderer in Greenland II


Question
How would you make this faster for one specific style image?
A new style image

Hokusai’s Great Wave off Kanagawa
A new content image

The seascape in Qingdao
Another neural style transfer

The seascape in Qingdao in the style of Hokusai’s Great Wave off Kanagawa
Autoencoder
An autoencoder takes a data/image, maps it to a latent space via an encoder module, then decodes it back to an output with the same dimensions via a decoder module.
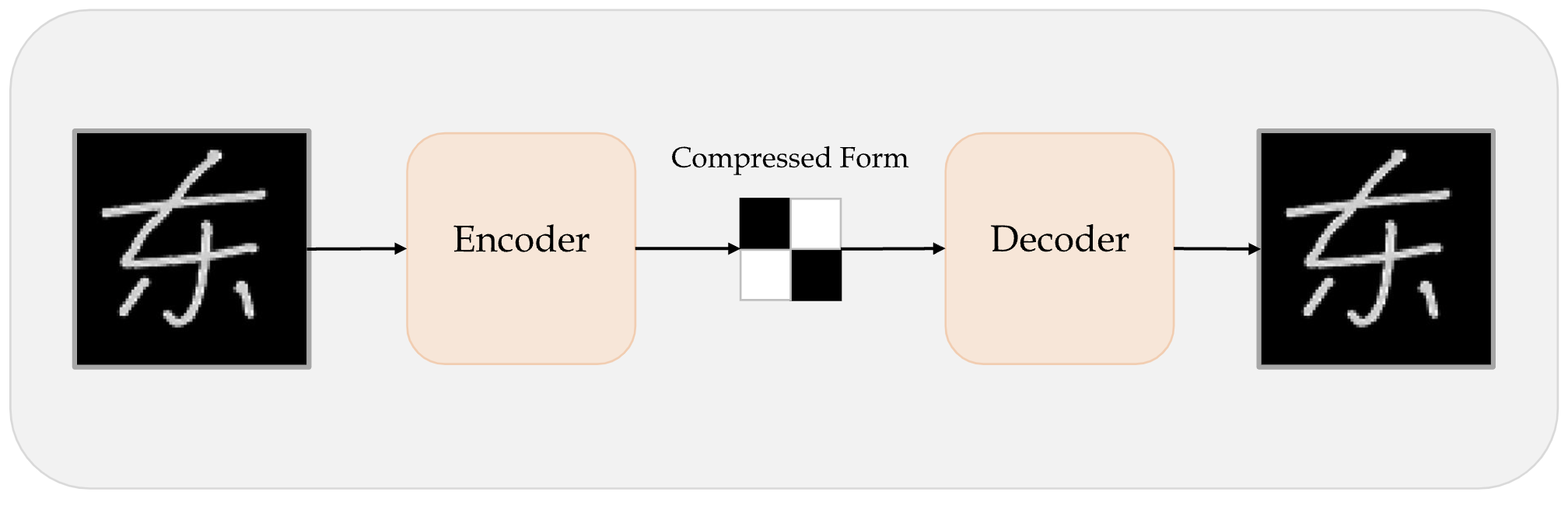
Schematic of an autoencoder.
Example: PSAM
Loading the dataset off-screen (using Lecture 6 code).


A compression game

Some recovered image


Invert the images


Some recovered image


Some recovered image
WARNING:tensorflow:5 out of the last 5 calls to <function TensorFlowTrainer.make_predict_function.<locals>.one_step_on_data_distributed at 0x70915cfc3e20> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has reduce_retracing=True option that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/guide/function#controlling_retracing and https://www.tensorflow.org/api_docs/python/tf/function for more details.
WARNING:tensorflow:6 out of the last 6 calls to <function TensorFlowTrainer.make_predict_function.<locals>.one_step_on_data_distributed at 0x70915cfc3e20> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has reduce_retracing=True option that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/guide/function#controlling_retracing and https://www.tensorflow.org/api_docs/python/tf/function for more details.

Intentionally add noise to inputs


{kind=link}
Variational autoencoder
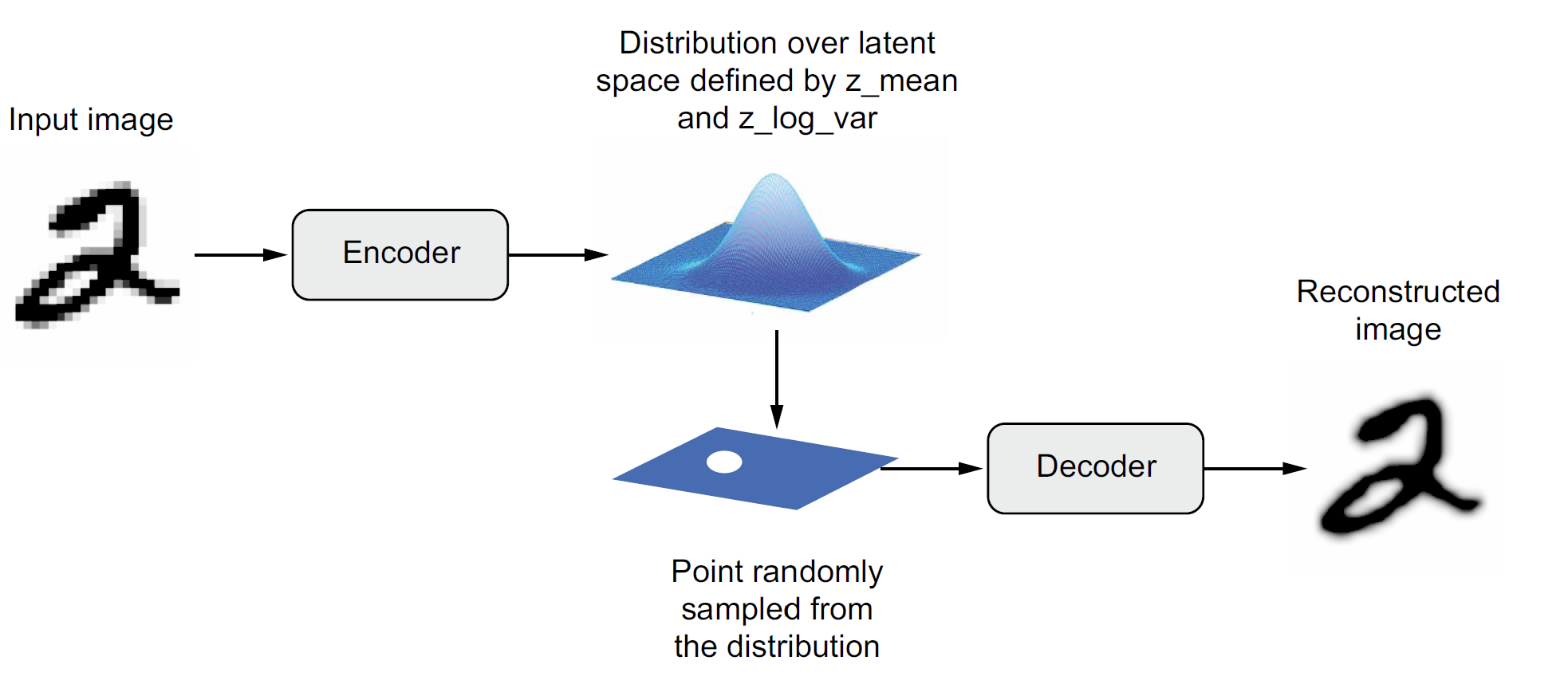
Schematic of a variational autoencoder.
VAE schematic process

Keras code for a VAE.
Focus on the decoder
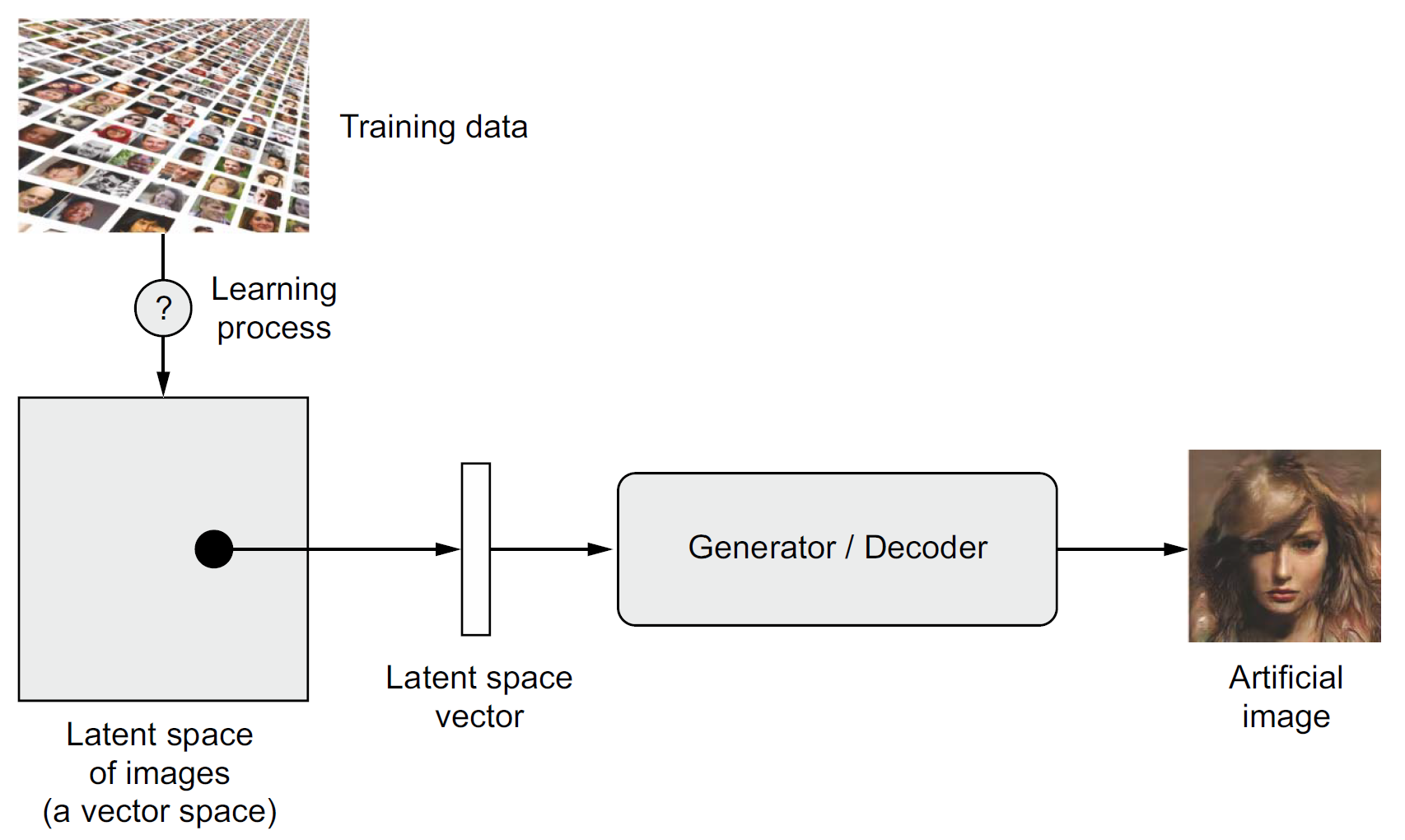
Sampling new artificial images from the latent space.
Exploring the MNIST latent space

Example of MNIST-like images generated from the latent space.
Glossary
- autoencoder (variational)
- beam search
- bias
- ChatGPT (& RLHF)
- DeepDream
- greedy sampling
- HuggingFace
- language model
- latent space
- neural style transfer
- softmax temperature
- stochastic sampling
![]()