array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])Recurrent Neural Networks
ACTL3143 & ACTL5111 Deep Learning for Actuaries
Shapes of data
Illustration of tensors of different rank.
Diagram of an RNN cell
The RNN processes each data in the sequence one by one, while keeping memory of what came before.

Schematic of a simple recurrent neural network. E.g. SimpleRNN, LSTM, or GRU.
A SimpleRNN cell.
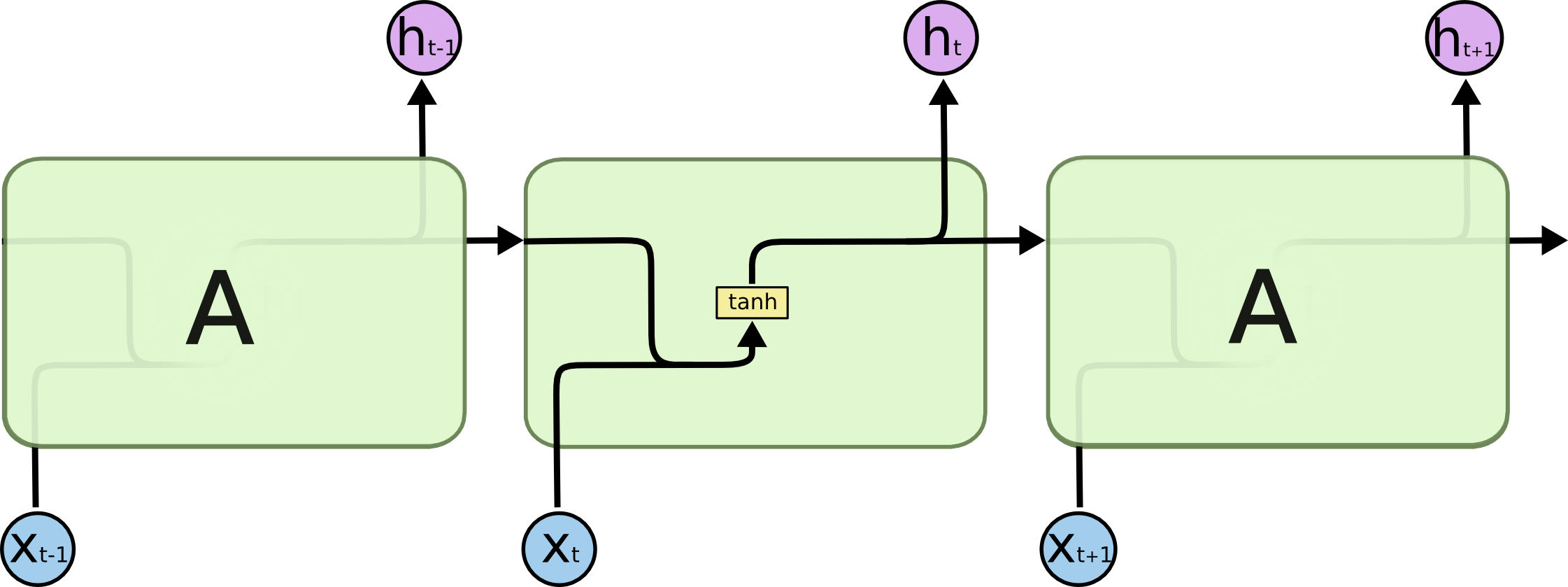
Diagram of a SimpleRNN cell.
All the outputs before the final one are often discarded.
LSTM internals
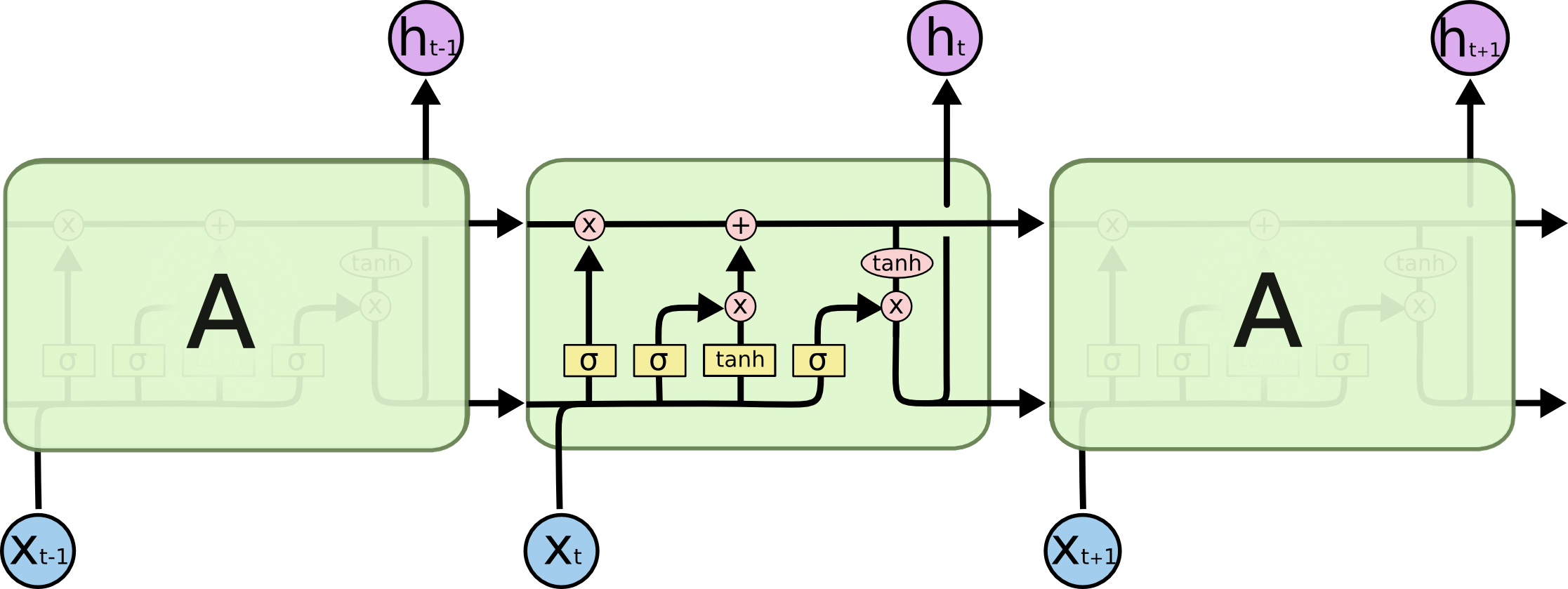

GRU internals

Diagram of a GRU cell.
Input and output sequences
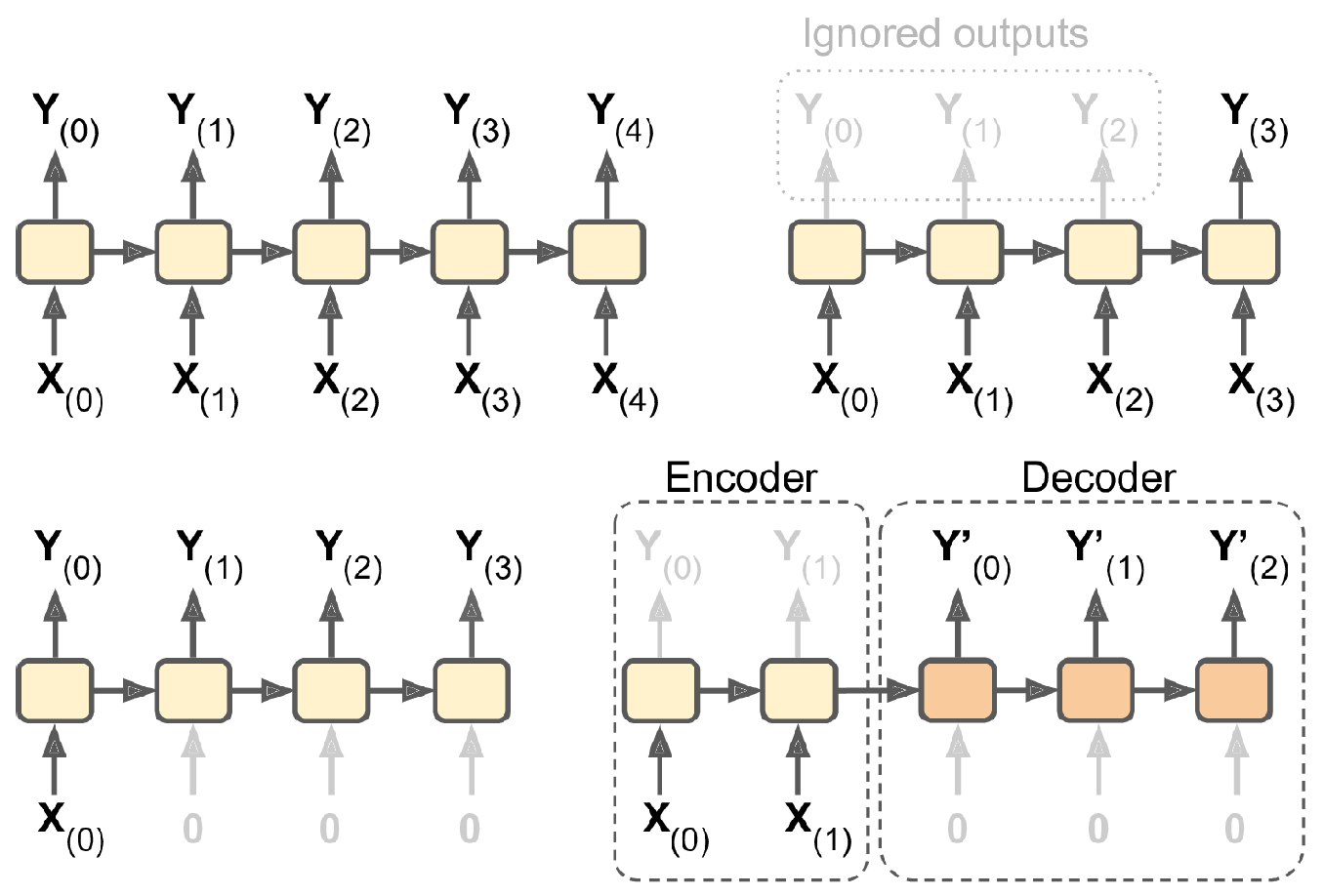
Categories of recurrent neural networks: sequence to sequence, sequence to vector, vector to sequence, encoder-decoder network.
Recurrent layers can be stacked.
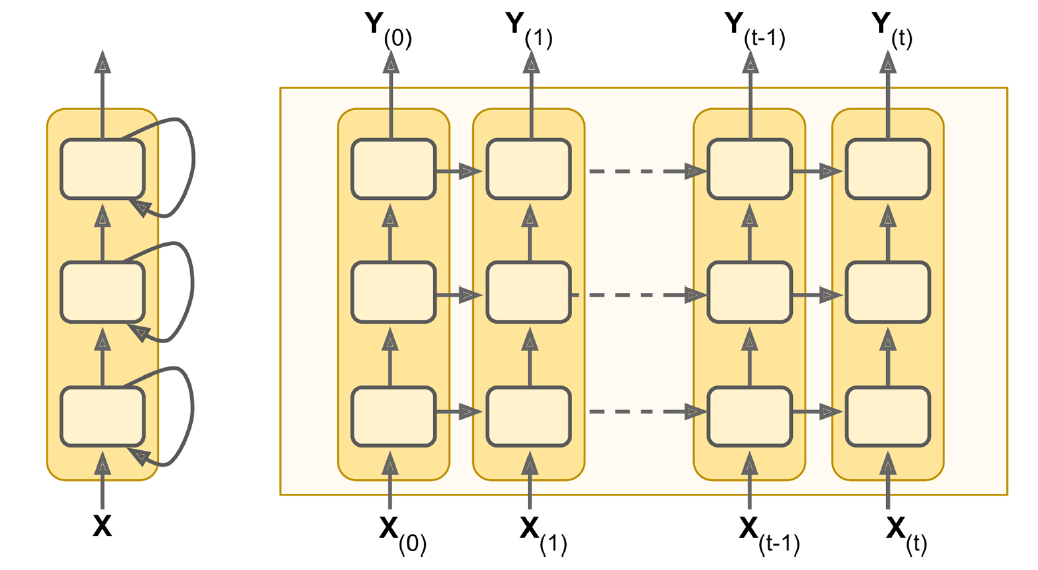
Deep RNN unrolled through time.
Australian House Price Indices

Percentage changes

The size of the changes
Brisbane 0.005496
East_Bris 0.005416
North_Bris 0.005024
West_Bris 0.004842
Melbourne 0.005677
North_Syd 0.004819
Sydney 0.005526
dtype: float64
Split without shuffling
num_train = int(0.6 * len(changes))
num_val = int(0.2 * len(changes))
num_test = len(changes) - num_train - num_val
print(f"# Train: {num_train}, # Val: {num_val}, # Test: {num_test}")# Train: 225, # Val: 75, # Test: 76
Plot the model

Assess the fits

Plotting the predictions

Assess the fits

Plot the model

Plotting the predictions
WARNING:tensorflow:5 out of the last 7 calls to <function TensorFlowTrainer.make_predict_function.<locals>.one_step_on_data_distributed at 0x7a2c503049a0> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has reduce_retracing=True option that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/guide/function#controlling_retracing and https://www.tensorflow.org/api_docs/python/tf/function for more details.
Assess the fits

Plotting the predictions
WARNING:tensorflow:6 out of the last 8 calls to <function TensorFlowTrainer.make_predict_function.<locals>.one_step_on_data_distributed at 0x7a2c882e79c0> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has reduce_retracing=True option that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/guide/function#controlling_retracing and https://www.tensorflow.org/api_docs/python/tf/function for more details.
Assess the fits

Plotting the predictions

Assess the fits

Plotting the predictions

Test set

Plot the model

Assess the fits

Plotting the predictions




Assess the fits

Plot the model

Plotting the predictions




Assess the fits

Plotting the predictions




Assess the fits

Plotting the predictions




Assess the fits

Plotting the predictions




Test set




Glossary
- GRU
- LSTM
- recurrent neural networks
- SimpleRNN
![]()